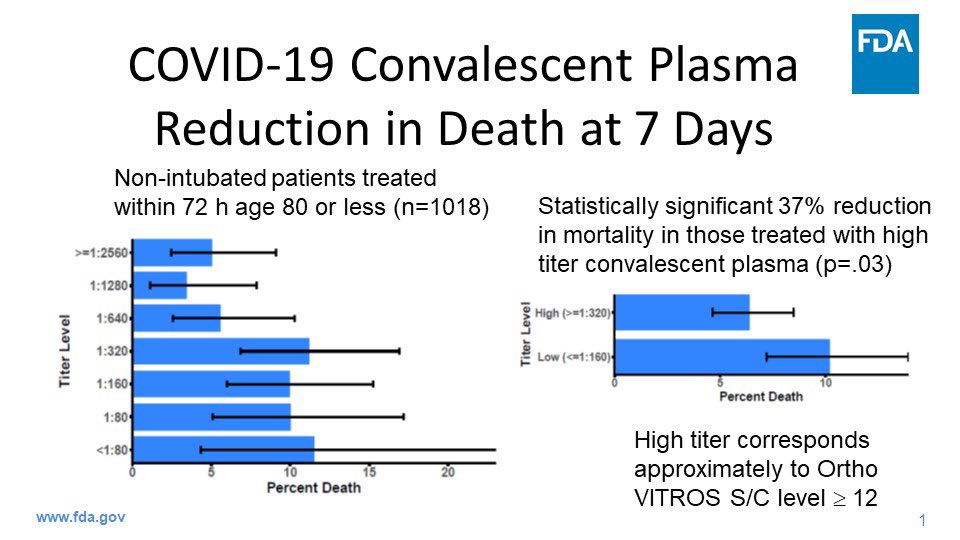
The last time our world experienced a virus of Covid-19 lethality, our public discourse was not that different than today’s. Of course I’m talking about the 1918 Spanish Flu. Even its name is a lie. It was called that in U.S. newspapers not because Spain was the origin of the virus but because Spain was a neutral party in World War I, which was blazing at the time.
How’s that, you say? While other countries embroiled in the conflict didn’t want to spook their citizens back home by honestly assessing the toll the deadly flu was taking on their troops, Spain was more forthright. More than most countries, Spain even took precautions such as strict quarantining and social distancing.
Following the dictum that no good deed goes unpunished, Spain got to “own” the flu appellation in the U.S. press because of those actions, in a xenophobic slight not unlike the way French fries — as beloved during the time of our multi-country occupation of Iraq as they are today — became known for a time as “freedom fries.” Why? France did not choose to join our little alliance. And we all know how successful that nation-building adventure was.
It makes you wonder when we will start paying attention to what our European neighbors are thinking. They occasionally may be onto something.
Hey, we’ve got this!
So what has this got to do with data visualizations? Just that powerful systems often try to deceive as a way to hold onto power. This can involve the systems disclosing data they possess to their constituents in a way that assures the inattentive Hey, we’ve got this! I’m going to show you an example from my recent work, but first, let me show you the data visualization pants-on-fire deception that got me typing in my basement instead of enjoying this sunny Saturday afternoon ..
This is a set of charts — one from July 2, and the other from today, July 18. In those two weeks, can you spot the 50% increase in cases per thousand? (I verified today’s number on the Georgia Department of Health website just now, and confirmed the July 2 screencap is legit as well).
Made more infuriating when you realize human lives are at stake, the graphic is right below this statement: “The charts below presents [sic] the number of newly confirmed COVID-19 cases over time. This chart is meant to aid understanding whether the outbreak is growing, leveling off, or declining and can help to guide the COVID-19 response.”
Okay, quiz time: Can you spot the increase in this before-and-after map?


If you haven’t caught it yet, I’ll give you the explanation that @andishehnouraee provided: “[Georgia Governor Brian] Kemp’s health department keeps changing the numbers on the map’s color legend to keep counties from getting darker blue or red. 2,961 cases was Red on July 2. Now a county needs 3,769 cases to show red. The result: an infographic that hides data instead of showing it.”
I find this indefensible. I will say other graphics on the same page definitely show a spike. But if I’m a Georgian and I look for my county on the only map on the page, how am I to know that my community has half again more confirmed cases than it did two weeks ago? This data visualization “shell game” may persuade inattentive citizens of a given county to not social distance, or wear a mask in public, and thereby cause further infection in an actual, honest-to-goodness public health crisis.
[Some Redditors have said these maps were designed to show county-to-county differences, but I’m not buying it. When you choose a color scale, either keep the numbers the same for the colors or don’t use numbers at all, and show percentages. The typical citizen isn’t going to spend more than a few seconds looking at the map, and will get the wrong story from this one.]
How to deceive using shifting scales, with Excel as your accomplice!
The above is an example of: If you don’t like the data, change the base numbers. Another, more common way is to not clearly show your bar charts or line charts starting from zero where the axes meet. Let’s say I am trying to improve my abysmal running pace, and share my progress with the world (These are real numbers, but give me a break … I’m an old nerd, not an elite runner!):
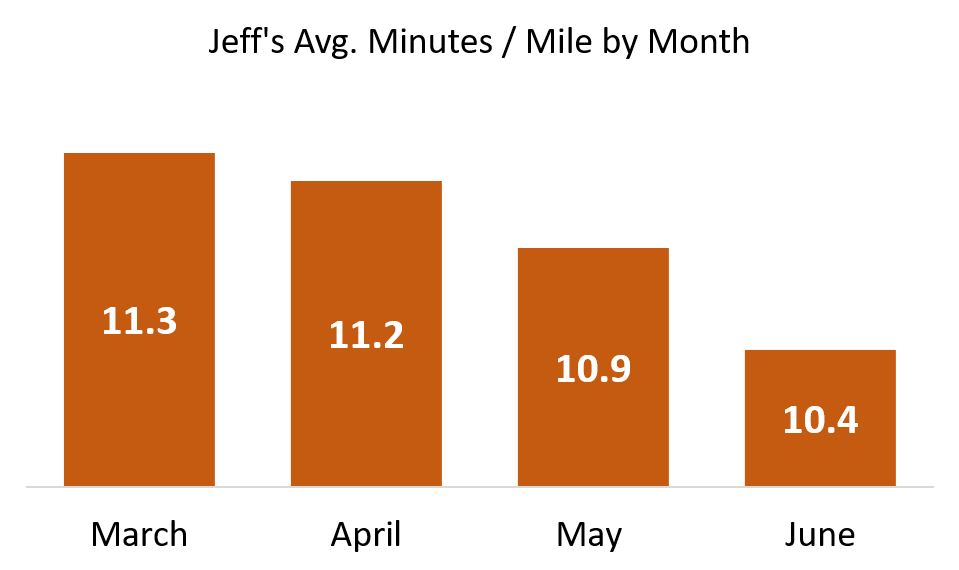
Look at this glorious chart! I can hear you exclaiming: What progress you’ve made, Jeff! But is it really that impressive? Of course not! When I popped these numbers into Excel and hit Insert Bar Chart, Excel did some editorializing. It started my Y-axis at 9.8 minutes per mile. And in doing so, it made me look like to the inattentive as though I’ve halved my time since March!
Let me repeat: Excel did this handicapping of my pathetic times automatically.
To get a real world view of my running — a world which includes rare athletes who have completed marathons at far less than half my personal best — here is the same graphic when the bars start at zero minutes per mile:
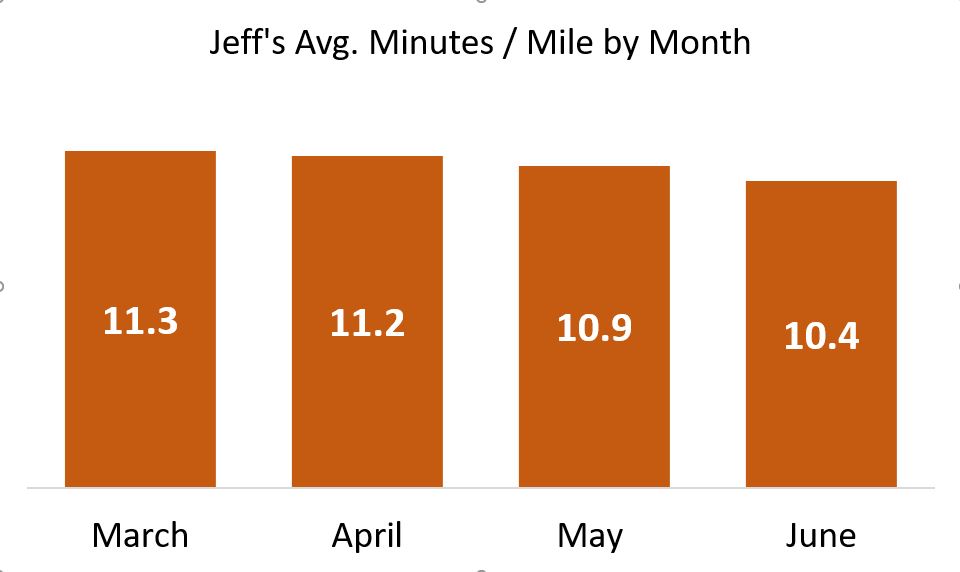
Not nearly the ego-boost, but it’s honest!
Scale breaks to the rescue
What if you just don’t have the room for all of that athletic plodding? In other words, what if my sad pace just wouldn’t fit on the slide, the bars being too tall? Yes, that’s a real thing, as I’ve pointed out in data visualization lectures:
Sometimes you want to take your audience all the way to the treetops, where the trunks are invisible but you can see which are the tallest of the majestic redwoods.
There’s this thing called a scale break (shown below with a made-up data set):
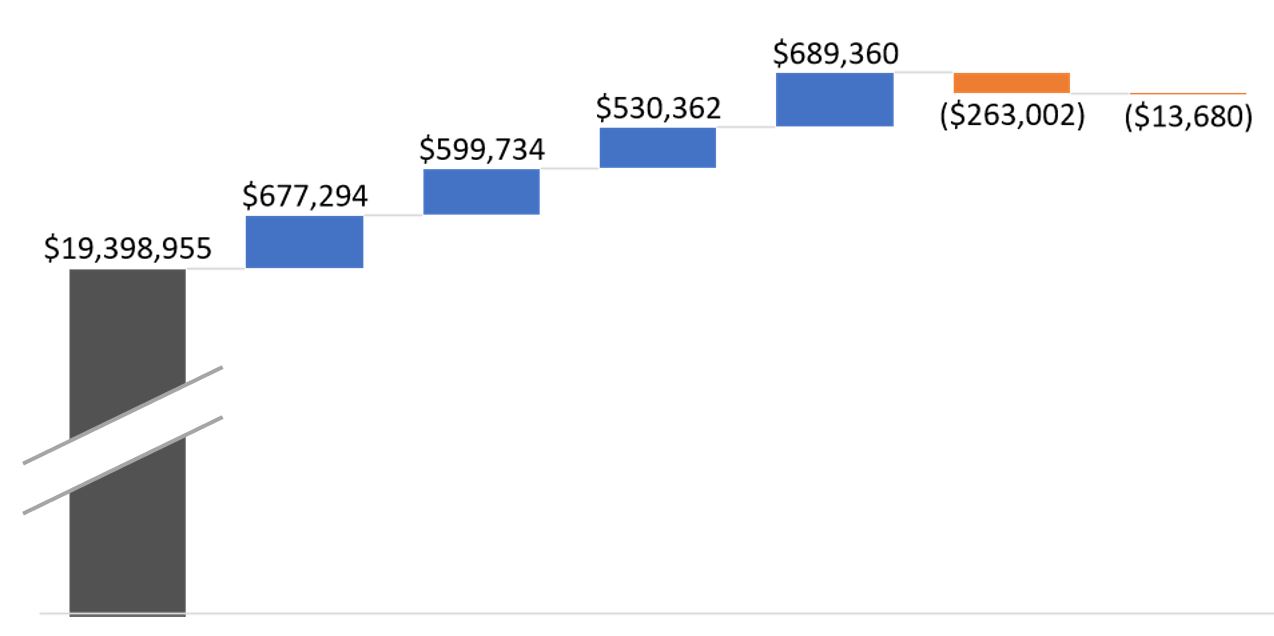
Now you can see a chart that tells an honest story without messing up the scale of your slide. And you can focus your audience’s attention on the data that matters.
Watch this blog for a follow-up, with more tips on how to lie with data visualizations!